Turtlebot3
In this example, we add a robot and start collecting robot data to Stdout.
You will also need 3 terminal windows, to:
- Run the Nav2 turtlebot3 launchfile: it starts localization, navigation and RViz
- Run navigation inspection demo
- Run DC
Using a different terminal window for DC helps reading its information.
Packages in the workspace
In addition to the ros2_data_collection repo in your workspace, you will need to download the aws warehouse package:
cd src
git clone https://github.com/aws-robotics/aws-robomaker-small-warehouse-world.git -b ros2
cd ..
colcon build
Setup the environment
Python dependencies
For this tutorial, we will need to install all dependencies:
pip3 install -r requirements.txt -r requirements-dev.txt
Setup the infrastructure
InfluxDB
InfluxDB will be used to store our data and timestamps. Later on, backend engineers can make requests on those JSON based on measurement requested and time range. To start it, follow the steps
Grafana
Grafana will be used to display the data as timeseries or statistics.
Setup simulation environment
In the terminal 1, source your environment, setup turtlebot configuration:
source /opt/ros/humble/setup.bash
source install/setup.bash
export GAZEBO_MODEL_PATH=$GAZEBO_MODEL_PATH:/opt/ros/humble/share/turtlebot3_gazebo/models
export GAZEBO_RESOURCE_PATH=${PWD}/src/aws-robomaker-small-warehouse-world/
export TURTLEBOT3_MODEL=waffle
source /usr/share/gazebo/setup.bash
Verify the gazebo world can be loaded properly:
gazebo /opt/ros/humble/share/aws_robomaker_small_warehouse_world/worlds/no_roof_small_warehouse/no_roof_small_warehouse.world
Gazebo will start with the warehouse environment. You can close it now.
I believe requiring the source along with those export are needed because of this issue
Terminal 1: Start Navigation
Then, in the same terminal (1), start the Turtlebot launchfile:
ros2 launch nav2_bringup tb3_simulation_launch.py \
world:=/opt/ros/humble/share/aws_robomaker_small_warehouse_world/worlds/no_roof_small_warehouse/no_roof_small_warehouse.world \
map:=/opt/ros/humble/share/aws_robomaker_small_warehouse_world/maps/005/map.yaml \
headless:=False \
x_pose:=3.45 \
y_pose:=2.15 \
yaw:=3.14
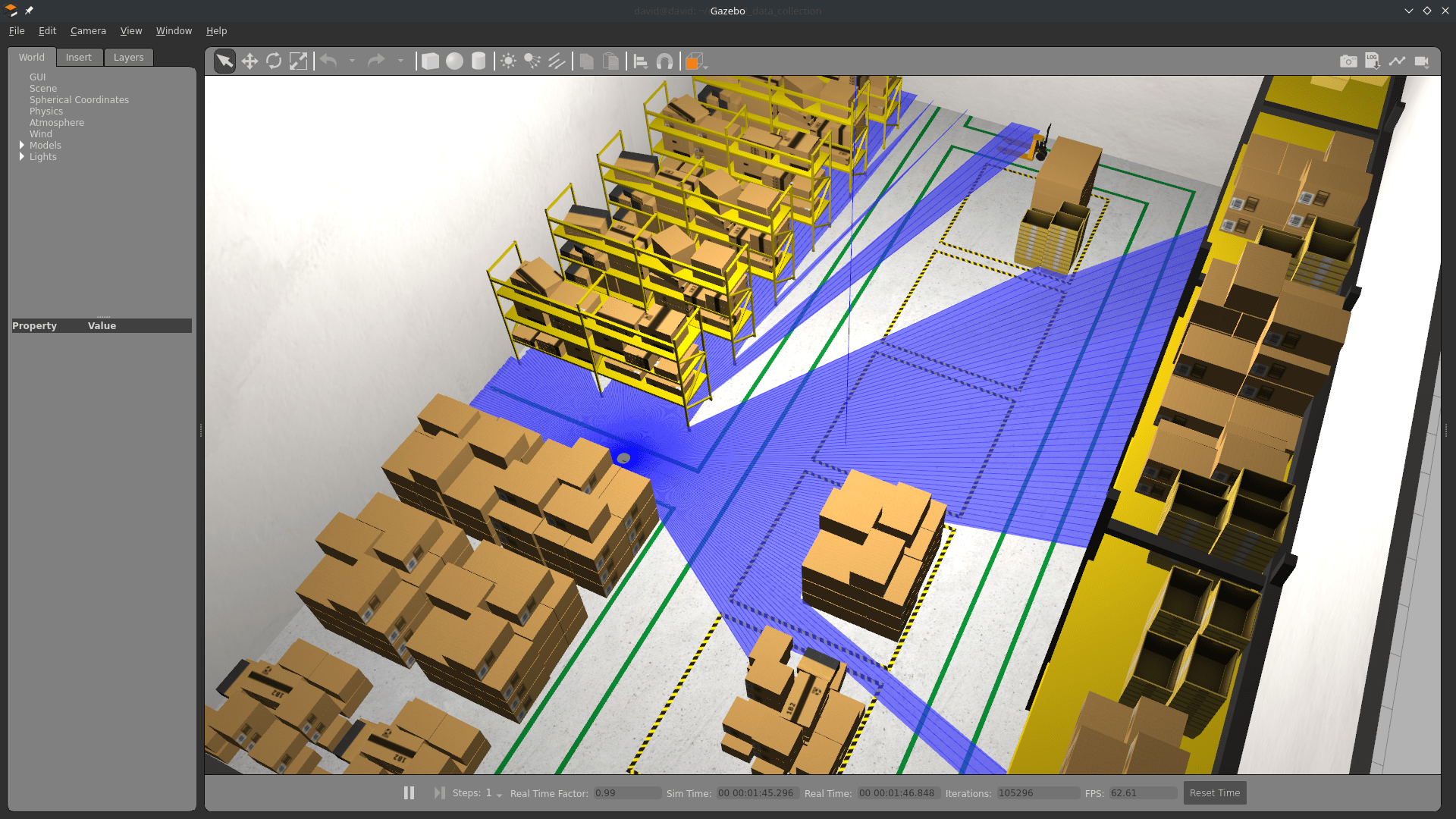
RViz and Gazebo will start: now you see the robot in Gazebo, and the map on RViz.
Terminal 2: Start DC
Run colcon build to compile the workspace:
colcon build
Now, start the demo:
ros2 launch dc_demos tb3_simulation_influxdb.launch.py
The robot will start collecting data.
Terminal 3: Start autonomous navigation
Execute
ros2 run nav2_simple_commander demo_security
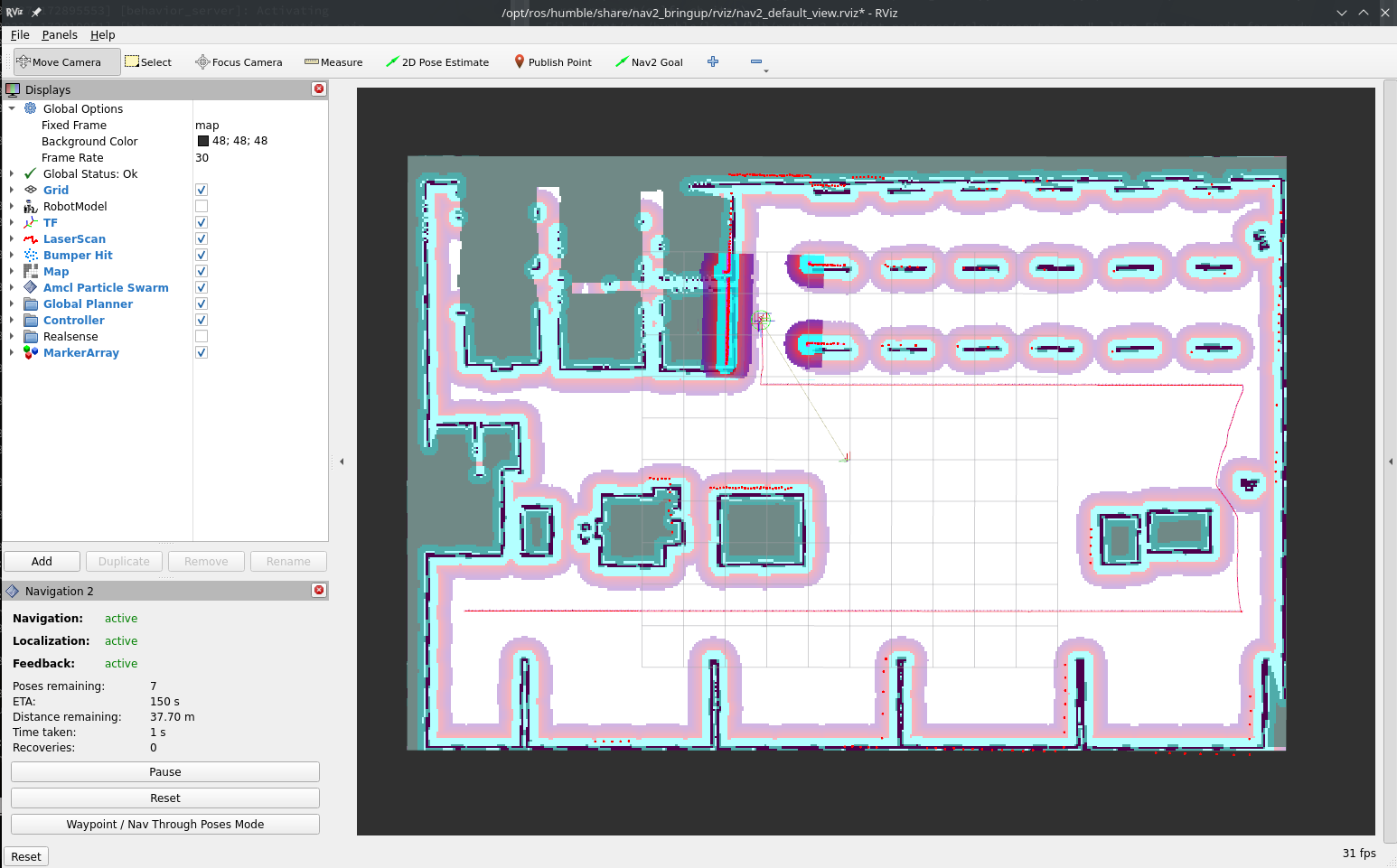
The robot will start moving and you will be able to see all visualizations activated in RViz:
Visualize the data
With Grafana Dashboard
Open your browser at http://localhost:3000 and login with admin/admin
Understanding the configuration
The full configuration file can be found here.
Measurement server
Measurements
measurement_plugins sets which plugin to load. We collect
System measurements:
Robot measurements:
Environment measurements:
Infrastructure measurements:
Each has their own configuration: polling interval, source topic, destination paths, topics used as input etc. Going through each of them would be too long here but you can check for each measurement its documentation and the general documentation of measurements
Note that all measurements have the nested and flattened parameter set to True, this will transform each measurement to conform to how InfluxDB stores data. See nested and flattened in the measurements page.
Note also that all images (map and camera images) are stored as base64 strings because Grafana, the frontend at the end will only be able to access strings from the database.
Conditions
We also initialize conditions:
- min_distance_traveled
- max_distance_traveled
They are used in the distance traveled measurement to only take values in a certain range.
Destination server
Here we only enable the InfluxDB plugins since it is where we send the data.
At the end, we want to display the data on Grafana. Grafana can only display content stored on the connected database. This also includes images, which is why they are stored as base64 strings.
InfluxDB destination
We pass all topics generated by measurements. The node will subscribe to it and transfer the data to InfluxDB.
Along with the inputs, we pass the server credentials.